SEO의 핵심은 바로 콘텐츠다. 하지만 단가가 높은 키워드일수록 콘텐츠만으로는 승부를 보기 어려워지고, 결국 기술적인 부분의 도움을 받을 수밖에 없게 된다. 여기서 기술적인 부분이란 웹사이트 속도의 최적화(퍼포먼스), 보안(SSL), 모바일 친화성, 웹페이지의 접근성(a11y)등 다양한 요소가 고려된다. 실제로 Google Lighthouse 검사를 해보면 위와 같은 부분들이 종합 점수에 큰 영향을 미치는 것을 볼 수 있다. 이와 더불어 기술적으로 내 웹사이트 검색 결과에서 [보여주어야 할 것]과 [보여주지 말아야 할 것]을 구분해서 검색 결과에 적절히 노출시켜주는 것 또한 SEO에 있어서 굉장히 중요한 부분이다.
검색 결과 중 [보여주어야 할 것]의 예시로는 검색엔진에 노출되어야 하는 내 웹사이트의 콘텐츠 그 자체가 될 것이고, [보여주지 말아야 할 것]의 예시로는 회원 탈퇴 페이지 혹은 관리자 화면 등이 있을 것이다. 조금 극단적인 예시이지만, 만약 내가 "스피머의 잡화상점"이라는 웹사이트를 통해 건전지를 팔고 있는데, 누군가 "스피머의 잡화상점"을 검색했을 때 검색 결과에 내가 팔아야 할 건전지보다 쓸데없는 로그아웃 페이지나 상품 등록 페이지가 검색 결과 상위에 나온다면 정작 중요한 상품 페이지 검색 결과가 검색 순위에서 밀려나 내 잡화상점 매출에도 그다지 좋은 영향을 미치지는 못할 것이다.
오늘 포스팅의 주제인 robots.txt가 바로 [보여주어야 할 것]과 [보여주지 말아야 할 것]을 구분할 수 있게 해주는 장치인 동시에, 며칠 전 작성한 meta tag: robots 포스팅과도 긴밀하게 연관된 항목이다.
Meta tag - robots 태그를 통한 검색 노출 관리 및 저품질 블로그 해결
Meta tag - robots 태그를 통한 검색 노출 관리 및 저품질 블로그 해결
* 들어가며: 이 글은 블로그 운영 및 HTML에 대한 기초적인 지식이 있는 분들을 대상으로 작성했습니다. 나는 현재 Medium, 티스토리, 개인 웹사이트, 깃허브 블로그(Jekyll) 및 네이버 블로그 등 다
spemer.tistory.com
작동방식
기본적으로 검색엔진(구글, 네이버 등)들은 웹페이지 문서들을 크롤링하는 로봇을 자체적으로 가지고 있으며, 크롤링한 웹페이지들은 각 검색엔진들의 알고리즘에 따라 색인 및 검색 시 검색 결과에 노출된다. 이렇게 웹페이지를 크롤링하는 로봇들에게 [보여주어야 할 것(크롤링해야 할 것)]과 [보여주지 말아야 할 것(크롤링하지 말아야 할 것)]의 범위를 지정해주는 것이 바로 robots.txt 파일이다. 그래서 기본적으로 robots.txt 파일에는 [검색엔진 크롤러(로봇)]의 이름과, 해당 크롤러가 [크롤링할 범위]가 명시되며, 각 크롤러들은 자신의 범위에 맞는 웹페이지들만을 크롤링해서 검색엔진의 검색 결과에 노출시켜주게 된다.
robots.txt 파일 생성 및 적용하기
robots.txt는 확장자에서 알 수 있듯 텍스트(.txt) 파일로 만들어야 하며, 이 파일은 웹사이트의 루트 디렉터리에 위치하고 있어야 한다. 사용 방법 및 문법은 아래와 같다.
기본 문법
# 명령을 내릴 크롤러를 지목
User-agent: [크롤러의 이름]
# 크롤러의 접근을 허용할 혹은 허용하지 않을 디렉토리를 설정
Allow: [접근을 허용할 디렉토리 혹은 파일의 위치]
Disallow: [접근을 허용하지 않을 디렉토리 혹은 파일의 위치]위의 기본 문법을 토대로, 구글의 크롤러 `Googlebot`으로 하여금 모든 웹페이지 크롤링을 허용하게끔 설정하는 robots.txt 파일은 아래와 같다. 검색엔진별 크롤러의 이름은 아래 간략하게 정리해두려 한다.
# Googlebot은 구글 크롤링 로봇의 이름이다.
User-agent: Googlebot
Allow: /위의 robots.txt 파일은 아래와도 같이 작성할 수 있다(동일하게 동작함).
# Disallow 항목의 값을 할당하지 않는것은, 아무것도 Disallow 하지 않겠다는 의미이다.
User-agent: Googlebot
Disallow:위를 응용해서 나의 웹사이트 전체가 구글 로봇(`Googlebot`)은 접근(크롤링) 가능하고, 네이버 로봇(`Yeti`)은 접근하지 못하도록 robots.txt를 작성하는 방법은 아래와 같다.
User-agent: Googlebot
Allow: /
User-agent: Yeti
Disallow: /위의 robots.txt 파일을 조금 더 응용해서 구글 로봇은 모든 웹페이지에 접근 가능하도록, 네이버 로봇은 모든 웹페이지에 접근하지 못하도록, 다음 로봇(Daumoa)은 `/about` 페이지에만 접근 가능하도록 설정해보자.
User-agent: Googlebot
Allow: /
User-agent: Yeti
Disallow: /
User-agent: Daumoa
Allow: /about
Disallow: /이제 이 robots.txt 파일을 여러분의 웹사이트 가장 최상단(루트 디렉터리)에 위치시킨 후 서버에 배포하게 되면, 이후로 구글의 크롤링 로봇은 웹사이트 전체를 크롤링하며, 네이버 크롤링 로봇은 어떤 웹페이지도 크롤링하지 않고, 다음 크롤링 로봇은 `/about` 페이지만 크롤링해서 검색 결과에 노출시켜주게 될 것이다.
User-agent(로봇) 목록
다음은 각 검색엔진 #크롤링 로봇(`User-agent`)들의 이름이다. 대상으로 하길 원하는 크롤러의 이름을 `User-agent` 항목의 값으로 적용하면 된다.
- Googlebot: Google 검색엔진의 크롤러
- Naverbot/Yeti: Naver 검색엔진의 크롤러(Yeti만 사용해줘도 된다)
- Daumoa: Daum 검색엔진의 크롤러
- Bingbot: Bing 검색엔진의 크롤러
- Zumbot: Zum 검색엔진의 크롤러
- Yandex: Yandex 검색엔진의 크롤러
- Slurp: Yahoo! 검색엔진의 크롤러
이 외에도 다양한 검색엔진과 다양한 크롤러들이 존재하지만, 우선 자주 사용될법한(+ 우리나라의) 크롤러들만 가져와서 나열해보았다.
기타 문법(비표준)
기본적으로 `User-agent`와 `Allow` 그리고 `Disallow` 이렇게 세 가지로 구성된 robots.txt이지만 추가적인 사항들을 명시할 수 있다. 여기서 비표준이라 함은, 모든 크롤러가 인식할 수 있는 명령어는 아니라는 의미 혹은 크롤러에 따라 다르게 인식 및 처리한다는 의미이다.
사이트맵 지정
`Sitemap`이라는 항목의 값으로 사이트맵이 위치한 곳을 적용해주면 된다.
User-agent: Googlebot
Allow: /
Sitemap: https://spemer.tistory.com/sitemap.xml크롤링 지연
`crawl-delay` 항목에 지연시간(초)을 적어주면 된다.
# Googlebot으로 하여금 1초마다 크롤링 하도록 제한
User-agent: Googlebot
Allow: /
crawl-delay: 1
실제 robots.txt 예시
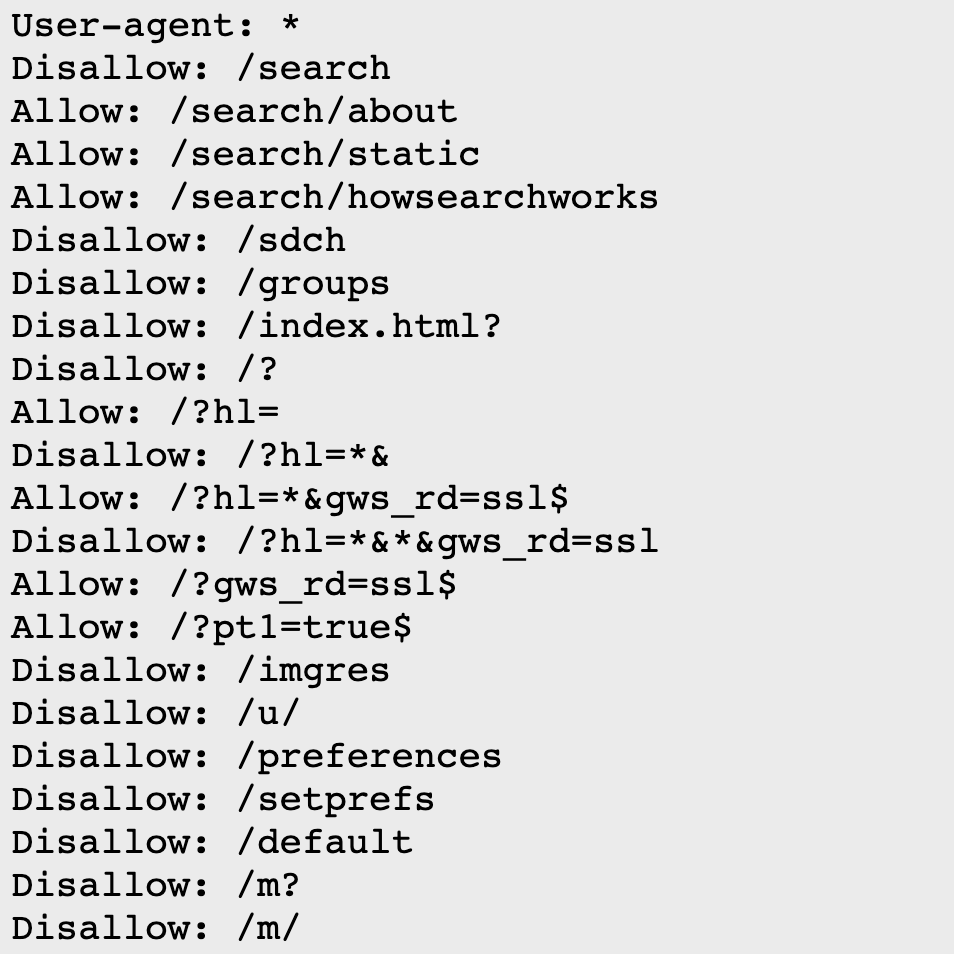
위에서 말한 바와 같이, 대부분의 웹사이트들은 도메인 뒤에 `/robots.txt` 를 붙이면 해당 웹사이트의 robots.txt 파일을 볼 수 있다. 아래 네이버 robots.txt를 준비해보았다.
네이버의 robots.txt
https://www.naver.com/robots.txt
User-agent: *
Disallow: /
Allow : /$네이버의 robots.txt 파일이다. `User-agent`는 와일드카드를 사용하여 모든 크롤러를 대상으로 하고 있으며, `Disallow`의 값으로는 `/` 을 설정해서 모든 페이지에 대해서 크롤러의 접근을 금지하고 있고, `Allow`의 값으로는 `/$`를 사용하여 최상위 디렉터리(`/` = `https://www.naver.com`)에만 크롤러의 접근을 별도로 허용하고 있다. `Allow`와 `$` 문자는 robots.txt 공식 웹사이트에는 설명되어있지 않은 스펙이지만, `$`(Dollar sign)을 사용할 경우 정확히 해당 주소만을 의미하게 되며, 그 뒤로 붙는 `/images` 혹은 `/files` 등의 디렉터리로는 접근할 수 없게 된다.
마치며
아래 robots.txt 공식 웹사이트에 가면 더욱 디테일한 문서를 볼 수 있다. 추가적으로 robots.txt 파일에 명시된 내용은 권고사항일 뿐, 법적인 근거나 강제력이 없지만 무단 크롤링 - 특히 크롤링한 DB의 상업적 이용 - 의 경우 저작권법(데이터베이스 권 침해)에 저촉될 수 있다는 점 또한 숙지하고 있는 것이 좋다.
The Web Robots Pages
The Web Robots Pages Web Robots (also known as Web Wanderers, Crawlers, or Spiders), are programs that traverse the Web automatically. Search engines such as Google use them to index the web content, spammers use them to scan for email addresses, and they
www.robotstxt.org
연관 아티클
Meta tag: robots 태그를 통한 검색 색인 및 노출 제어하기 저품질 블로그 해결하기
들어가며: 이 글은 블로그 운영 및 HTML에 대한 기초적인 지식이 있는 분들을 대상으로 작성되었다.
spemer.github.io
'재테크 > 블로그' 카테고리의 다른 글
| [유튜브] 영상 링크 삽입/최종 화면 및 카드 만들기 (0) | 2022.02.15 |
|---|---|
| 구글 애드센스: “주소가 확인되지 않아 지급이 보류 중입니다” 문제 해결방법 (0) | 2021.10.28 |
| 네이버 애드포스트, 두 달 만에 승인 완료 (0) | 2021.10.22 |
| [개인 블로거] 구글 애드센스 미국세금정보 등록 간단요약 (0) | 2021.09.23 |
| Meta tag - robots 태그를 통한 검색 노출 관리 및 저품질 블로그 해결 (0) | 2021.09.18 |




댓글